Management and Business Research
Additional Guidance
CAQDAS Package
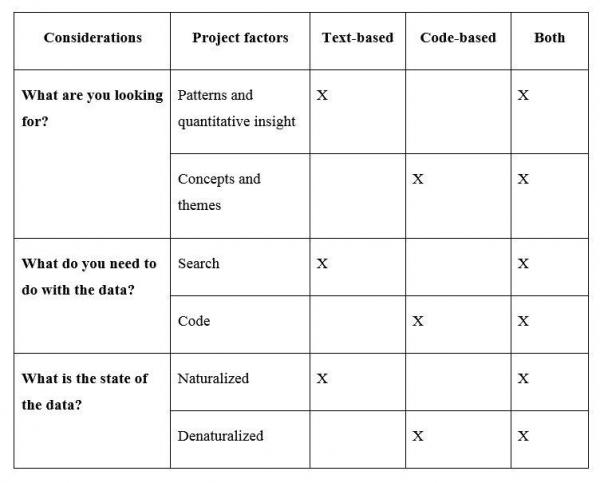
Imagine for a moment that you have just conducted a case study, and you have generated data using semi-structured interviews and observation. You decided early on that you are particularly interested in gaining a deeper understanding of the substantive area, and therefore you have opted for a grounded theory method of analysis. Now you are faced with the first consideration: what are you looking for from your data? There is little empirical evidence in your substantive area from which to structure search queries or inform rigorous, in-depth searching of the data; therefore, you are more interested in what will emerge from the data. Thus, in this scenario, you are more concerned with conceptualization and thematic analysis of the data. The answer to the first consideration then brings you to the second consideration: will you be primarily searching or coding the data? Coding relates to the practice of assigning ‘codes’, which are essentially descriptions, to selections of data; this is usually conducted in an iterative fashion and results in the conceptualization of data. Consequently, for this consideration, you necessarily decide you are looking for emergent concepts from the data.
You arrive at the data-preparation stage. You need to decide whether you code your interviews as audio files, assigning codes to certain sequences (such as ‘INNOVATION STRATEGY’ for minute 02.30 to minute 5:30) or whether you transcribe your data. Not all packages support the coding of audio material, and if you aim at a very detailed and in-depth analysis of the material, coding audio files might not be practical. If you decide to transcribe your data, you still need to consider the level of detail. Do you want to create summary records for your interviews because you are interested in very specific aspects, or do you choose to fully transcribe them? If you decide to transcribe them, what level of detail will be required? As we have seen above, conversation analysis requires naturalized transcripts that record every slightest detail, such as involuntary vocalizations. In contrast, for a grounded analysis aiming at the identification of common themes, less detail is required (denaturalized transcripts).
Similarly, decisions will have to be made about the field notes. If, for example, you decide just to scan your handwritten notes, you will be able to code them like pictures – a certain section of the scan can be selected and then a code can be assigned. The limitation of this technique is that several packages do not support such coding, and none of them will read in your handwritten notes. As a result, when you retrieve material by code, you will be able to retrieve only pictures (instead of quotations). Therefore, most researchers still type up their field notes so that they can take advantage of the advanced search and query tools included in most packages. Having addressed these considerations, you may be somewhat clearer on the choice of software package. On the most general level, your aims, data and analytical approach suggest the use of a ‘code-based’ package such as NVivo or ATLAS.ti. You will then have to check which code-based package offers the best support for coding the kind of data you have created and wish to analyse.
To demonstrate the other extreme, briefly consider this alternative scenario. You have conducted the same study, using the same methods. However, this time there is a substantial empirical foundation to the substantive area, and your study is particularly concerned with analysing discourse. Prior to undertaking the study, you have conducted a literature review and have generated a list of keywords that you would like to search for during the discourse analysis; in other words, you are looking for patterns and word frequencies (quantitative insight). Consequently, you decide that you will primarily conduct word searches during your analysis. Last, your overall analytical approach necessitates naturalistic description, because every small detail may be of importance. With this different set of answers, you conclude that you will need to use a software package that is purpose-built for the deeper level of textual analysis that you require; such packages are known as ‘text-based’ packages. Table 8.8 provides an overview of the considerations discussed. You will notice that there is a column labelled ‘Both’, which suggests there are CAQDAS packages that cater for all needs. While this is the case, it is only so to a certain extent: code-based packages such as NVivo and ATLAS.ti also have some of the functionality found in text-based packages, such as keyword search and the capacity to search for strings of words. However, an important point that should be borne in mind here is that while such packages can be considered as ‘hybrids’, they are not purpose-built for handling both text- and code-based work. For example, the use of a package such as WordSmith could facilitate more in-depth, broad work on a textual level.
Types of CAQDAS packages